
Rensis Likert introduced the summated rating scale in 1932. Nearly a century later, the Likert scale remains the most widely used question format in survey research. You have filled them out hundreds of times: "On a scale of 1 to 5, how satisfied are you with our service?"
But the simplicity of the format hides real design decisions that affect the quality of your data. The number of points, the labels you use, whether you include a midpoint, and how you lay out the scale on the page all influence how respondents answer and how reliable those answers are.
The good news is that these questions have been studied extensively. Here is what the psychometric research says about designing Likert scales that produce accurate, reliable data.
How Many Points? The 5 vs 7 Debate
The most common Likert scale lengths are 5 and 7 points. Researchers have tested scales ranging from 2 points to 11 points and beyond. The evidence is clear on some things and nuanced on others.
Preston and Colman (2000), published in Educational and Psychological Measurement, tested scales with 2, 3, 4, 5, 6, 7, 8, 9, and 10 response categories. They found that scales with fewer than 5 points produced lower reliability and validity. Scales with 7 to 10 points performed best on measures of reliability, validity, and respondent preference. But the gains beyond 7 points were marginal.
Krosnick and Presser (2010), in the Handbook of Survey Research, reviewed a large body of evidence and concluded that 5-point and 7-point scales are generally optimal. Scales with fewer points lose information. Scales with more points create cognitive burden without proportional gains in measurement precision.
Simms, Zelazny, Williams, and Bernstein (2019) found that 6-point scales (with no midpoint) produced slightly higher reliability than 5-point scales in personality measurement, but the practical difference was small.
The practical recommendation: Use 5 points for simple evaluations where respondents need to answer quickly (customer feedback, event ratings, classroom evaluations). Use 7 points when you need finer discrimination and your respondents have time and motivation to distinguish between levels (academic research, psychometric instruments, organizational surveys).
To Include a Midpoint or Not
A 5-point scale has a midpoint (typically labeled "Neutral" or "Neither agree nor disagree"). A 4-point or 6-point scale forces respondents to lean one direction or the other.
The argument for removing the midpoint is that it reduces "fence-sitting," where respondents choose the middle option to avoid committing to a position. The argument for including it is that some respondents genuinely hold neutral opinions, and forcing them to choose a side introduces measurement error.
Kulas and Stachowski (2009), published in the Journal of Research in Personality, found that including a midpoint did not significantly reduce the reliability of scales. Respondents who selected the midpoint were genuinely less extreme in their attitudes, not simply avoiding the question.
Krosnick (1991) documented a phenomenon called "satisficing," where respondents choose the easiest acceptable answer rather than the most accurate one. Midpoints can attract satisficers who use it as a shortcut. However, removing the midpoint does not eliminate satisficing; it just forces it into adjacent categories.
Nadler, Weston, and Voyles (2015) found that scales with midpoints produced equivalent reliability to scales without them, and respondents reported a slight preference for scales that included a neutral option.
The practical recommendation: Include a midpoint for most surveys. Remove it only when you specifically need to force a directional response and your respondents understand why.
Label Every Point or Just the Endpoints
Some scales label only the two endpoints ("Very dissatisfied" to "Very satisfied"). Others label every point. The research favors full labeling.
Krosnick and Presser (2010) found that fully labeled scales produce higher reliability than partially labeled ones. When only endpoints are labeled, respondents must infer what the intermediate points mean. Different respondents make different inferences, introducing noise.
Menold, Kaczmirek, Lenzner, and Neusar (2014) confirmed that fully labeled scales reduced measurement error compared to endpoint-only labeled scales, particularly for respondents with lower educational attainment.
On paper surveys, fully labeling each point also has a practical advantage: it makes the form self-explanatory. A respondent does not need to mentally interpolate between "Strongly agree" and "Strongly disagree" to figure out what a "3" means.
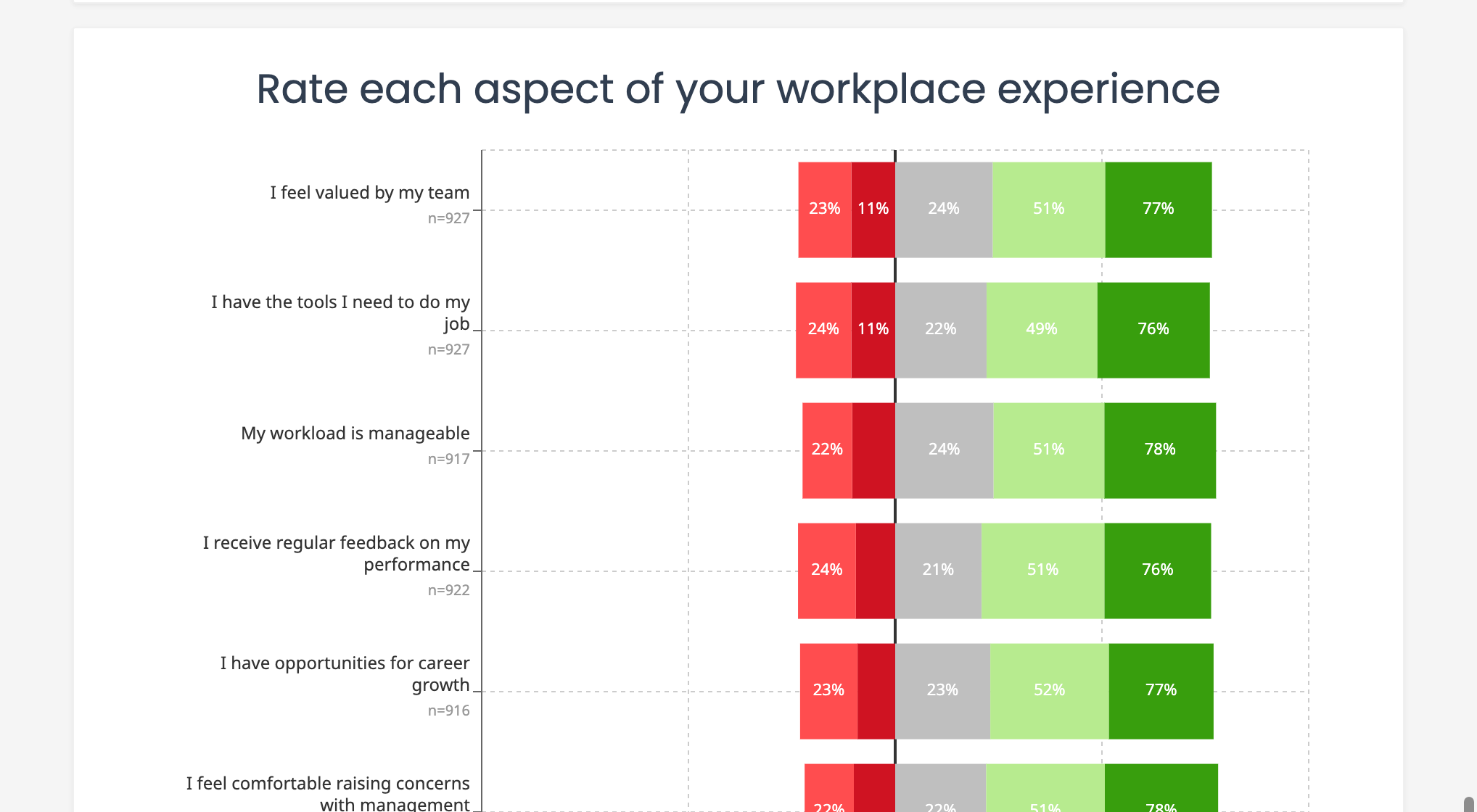
The practical recommendation: Label every point. Use clear, unambiguous labels that form a logical progression. Avoid labels that respondents might interpret inconsistently.
Scale Direction and Visual Layout
Should your scale go from negative to positive (1 = Strongly disagree, 5 = Strongly agree) or positive to negative? Does it matter whether the positive end is on the left or right?
Hartley and Betts (2010) found a modest primacy effect in Likert scales: respondents are slightly more likely to select options presented earlier in the visual sequence. For left-to-right readers, this means the leftmost option gets a small advantage.
For paper surveys, this has a design implication. If you place the positive option on the left and the negative on the right, you may get slightly inflated positive responses compared to the reverse layout. The effect is small but measurable in large samples.
Tourangeau, Couper, and Conrad (2004) found that visual design features like spacing, alignment, and grouping affected how respondents interpreted and used rating scales. Scales where options were evenly spaced produced more reliable data than scales with uneven visual spacing.
The practical recommendation: Be consistent within your survey. If "Strongly agree" is on the left for one question, keep it on the left for all questions. Ensure even visual spacing between all points. For paper forms, use checkboxes or circles of equal size with equal spacing.
Agree/Disagree vs Item-Specific Scales
The most common Likert format asks respondents to agree or disagree with a statement: "The training was useful" (Strongly disagree to Strongly agree). An alternative approach uses item-specific scales: "How useful was the training?" (Not at all useful to Extremely useful).
Saris, Revilla, Krosnick, and Shaeffer (2010) found that agree/disagree scales are more susceptible to acquiescence bias, the tendency for some respondents to agree with statements regardless of content. This bias is stronger among respondents with lower education and in cultures where deference to authority is valued.
Krosnick (1999) recommended item-specific scales as the default because they reduce acquiescence bias and produce higher validity. Instead of "Our customer service is excellent" (agree/disagree), use "How would you rate our customer service?" (Poor to Excellent).
The practical recommendation: Use item-specific scales when possible. Reserve agree/disagree formats for statements where agreement is the natural response dimension (attitudes, beliefs, opinions).
Paper vs Screen: Does the Medium Affect Responses?
Research comparing Likert scale responses on paper versus screen has generally found equivalence in the data produced, with some notable differences in how respondents interact with the scales.
Denniston, Brener, Kann, Smith, and Lowry (2010) compared paper and computer-based administration of health behavior questionnaires and found no significant differences in response distributions for Likert-type items.
However, Tourangeau et al. (2004) found that visual presentation matters more on screen, where respondents may see different layouts depending on device and screen size. A scale that looks balanced on a desktop may appear lopsided on a phone. Paper scales are visually fixed: every respondent sees exactly the same layout.
For mixed-mode surveys where you collect responses on both paper and web, keeping the visual layout as similar as possible between modes reduces measurement differences. PaperSurvey.io supports both paper and web responses for the same survey, allowing you to design one instrument that works across both modes.
Common Mistakes in Likert Scale Design
Psychometric research identifies several common errors:
Double-barreled items. "The instructor was knowledgeable and engaging" asks about two things at once. A respondent who thinks the instructor was knowledgeable but not engaging cannot answer accurately. Ask one question per item.
Leading wording. "Don't you agree that our service is excellent?" biases toward agreement. Use neutral wording: "How would you rate our service?"
Inconsistent scale direction. Mixing scales where 1 = best and 1 = worst within the same survey confuses respondents and increases error rates (Weijters, Cabooter, & Schillewaert, 2010).
Too many items measuring the same construct. Survey fatigue increases with length. Cronbach's alpha (a measure of internal consistency) can be acceptable with as few as 3-4 well-designed items per construct. Adding more items produces diminishing returns in reliability while increasing respondent burden (Streiner, 2003).
Using scales for factual questions. "How many times did you visit the doctor this year?" should not be answered on a Likert scale. Use specific response options or open numeric fields for factual questions.
Designing Likert Scales for Paper Forms
Paper forms have specific constraints that affect Likert scale design:
- Space is limited. A 7-point scale with full labels takes more horizontal space than a 5-point scale. If your form has many Likert items, a 5-point scale may fit better without cramping the layout.
- Checkbox alignment matters. On paper, respondents mark boxes or circles with a writing instrument. Larger, well-spaced checkboxes reduce ambiguous marks that require manual verification during processing.
- Grid layouts save space. When you have multiple items on the same scale, a grid (matrix) layout with items as rows and scale points as columns is both space-efficient and easy for respondents to complete.
- Instruction clarity. Include a brief instruction above the scale: "Please mark one box per row." On paper, you cannot enforce this with form validation, so clear instructions reduce double-marking.
PaperSurvey.io supports single-choice grids (Likert matrices) that print with properly spaced checkboxes and process automatically via OMR. Each response is read from the scanned form without manual data entry.
References
- Denniston, M. M., Brener, N. D., Kann, L., Smith, G., & Lowry, R. (2010). Comparison of paper-and-pencil versus web administration of the Youth Risk Behavior Survey. Journal of Adolescent Health, 47(4), 424-428.
- Hartley, J., & Betts, L. R. (2010). Four layouts and a finding: The effects of changes in the order of the verbal labels and numerical values on Likert-type scales. International Journal of Social Research Methodology, 13(1), 17-27.
- Krosnick, J. A. (1991). Response strategies for coping with the cognitive demands of attitude measures in surveys. Applied Cognitive Psychology, 5(3), 213-236.
- Krosnick, J. A. (1999). Survey research. Annual Review of Psychology, 50, 537-567.
- Krosnick, J. A., & Presser, S. (2010). Question and questionnaire design. In P. V. Marsden & J. D. Wright (Eds.), Handbook of Survey Research (2nd ed.). Emerald.
- Kulas, J. T., & Stachowski, A. A. (2009). Middle category endorsement in odd-numbered Likert response scales. Journal of Research in Personality, 43(3), 489-493.
- Likert, R. (1932). A technique for the measurement of attitudes. Archives of Psychology, 22(140), 1-55.
- Menold, N., Kaczmirek, L., Lenzner, T., & Neusar, A. (2014). How do respondents attend to verbal labels in rating scales? Field Methods, 26(1), 21-39.
- Nadler, J. T., Weston, R., & Voyles, E. C. (2015). Stuck in the middle: The use and interpretation of mid-points in items on questionnaires. Journal of General Psychology, 142(2), 71-89.
- Preston, C. C., & Colman, A. M. (2000). Optimal number of response categories in rating scales. Acta Psychologica, 104(1), 1-15.
- Saris, W. E., Revilla, M., Krosnick, J. A., & Shaeffer, E. M. (2010). Comparing questions with agree/disagree response options to questions with item-specific response options. Survey Research Methods, 4(1), 61-79.
- Simms, L. J., Zelazny, K., Williams, T. F., & Bernstein, L. (2019). Does the number of response options matter? Psychological Assessment, 31(4), 557-566.
- Streiner, D. L. (2003). Starting at the beginning: An introduction to coefficient alpha and internal consistency. Journal of Personality Assessment, 80(1), 99-103.
- Tourangeau, R., Couper, M. P., & Conrad, F. (2004). Spacing, position, and order: Interpretive heuristics for visual features of survey questions. Public Opinion Quarterly, 68(3), 368-393.
- Weijters, B., Cabooter, E., & Schillewaert, N. (2010). The effect of rating scale format on response styles. International Journal of Research in Marketing, 27(3), 236-247.
Start your free trial and design your first Likert scale survey for paper or web.